集成模型XGBoost 机器学习热门研究方向入门指南与学习路线图
引言
在当今人工智能(AI)和机器学习的浪潮中,集成模型凭借其出色的预测性能和稳定性,成为了众多研究与应用领域的核心工具。其中,XGBoost(eXtreme Gradient Boosting)以其卓越的效率、灵活性和在各类数据竞赛(如Kaggle)中的统治性表现,稳居最热门的研究方向之一。无论是希望入门机器学习的新手,还是寻求进阶的开发者,掌握XGBoost都至关重要。本文将为你系统性地梳理XGBoost的核心概念、应用优势,并附上一份清晰的学习路线图,助你从入门到实践。
第一部分:XGBoost是什么?为何如此重要?
XGBoost是一种优化的分布式梯度提升库,属于集成学习中Boosting家族的一员。其核心思想是串行构建多个弱学习器(通常是决策树),每一个新模型都致力于纠正前一个模型的错误,最终将这些模型的结果加权求和,得到一个强大的强学习器。
其重要性体现在以下几个方面:
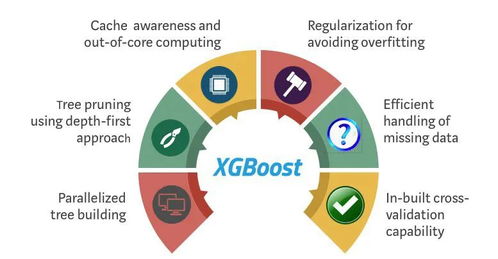
1. 高性能:在许多结构化数据(表格数据)的分类和回归任务中,XGBoost的表现常常优于深度学习等复杂模型。
2. 高效灵活:算法设计上进行了大量优化(如稀疏感知、并行处理、缓存优化),训练速度快,能处理大规模数据。支持自定义目标函数和评估准则。
3. 广泛的适用性:在金融风控、广告点击率预测、商品推荐、疾病预测等众多领域都有成功应用。
4. 可解释性:相比“黑箱”深度神经网络,基于树的集成模型能提供特征重要性评分,有助于理解模型决策过程。
第二部分:XGBoost核心概念快速入门
在深入学习前,你需要理解几个关键概念:
- 梯度提升(Gradient Boosting):通过梯度下降来最小化损失函数,指导新树的生成方向。
- 决策树(CART):XGBoost的基学习器,用于进行特征分裂和预测。
- 正则化:XGBoost在目标函数中引入了正则项(L1/L2),用于控制模型复杂度,有效防止过拟合。
- 特征重要性:通过计算特征在树结构中被用于分裂的次数或带来的增益,评估其对预测的贡献。
- 超参数:如学习率(
eta)、树的最大深度(max_depth)、子采样比例(subsample)等,对模型性能有决定性影响,需要通过调优(如网格搜索、贝叶斯优化)来确定。
第三部分:XGBoost学习路线图
以下是一个循序渐进的学习路径,结合理论学习与实践编码:
第一阶段:基础准备(1-2周)
1. 掌握前置知识:确保你具备Python编程基础、NumPy/Pandas数据处理技能,以及对机器学习基本概念(如监督学习、过拟合/欠拟合、交叉验证)的理解。
2. 环境搭建:安装Python科学计算环境(推荐Anaconda),使用pip install xgboost命令安装XGBoost库。
第二阶段:核心学习与实践(2-3周)
1. 官方文档与教程:从阅读XGBoost官方文档开始,这是最权威的学习资源。重点关注Python API介绍和参数说明。
2. 动手实践:
- 第一步:在CSDN、Datawhale等社区或博客平台,寻找一个完整的XGBoost分类/回归入门项目(如使用经典的泰坦尼克号生存预测或波士顿房价数据集)。跟随教程,完成数据加载、预处理、模型训练、预测和评估的完整流程。
- 第二步:深入理解关键超参数,并尝试使用
GridSearchCV或RandomizedSearchCV进行调优,观察模型性能变化。
- 第三步:学习使用XGBoost的可视化工具,如绘制特征重要性图和单棵树的结构图,增强模型理解。
第三阶段:进阶与深入(长期)
1. 理论深化:阅读陈天奇(XGBoost作者)的原始论文《XGBoost: A Scalable Tree Boosting System》,深入理解算法原理、系统设计和优化细节。
2. 对比学习:了解与XGBoost相关的其他集成模型,如LightGBM(微软出品,速度更快)和CatBoost(擅长处理类别特征),理解它们的异同与适用场景。
3. 参与项目与竞赛:
- 在Kaggle、天池等数据竞赛平台上,寻找使用XGBoost/集成模型的比赛,通过实战提升工程能力。
- 将XGBoost应用到你的专业领域或感兴趣的课题中,解决实际的预测问题。
- 关注前沿:通过关注AI顶会(如NeurIPS, ICML, KDD)和优秀博客,了解集成学习和树模型的最新研究进展(例如,在深度学习中结合树模型的研究)。
第四部分:资源推荐
- 优质社区与博客:
- Datawhale:一个开源学习组织,经常发布优质、系统的机器学习学习资料和组队学习项目。
- CSDN博客:拥有海量中文技术博客,搜索“XGBoost 详解”、“XGBoost 实战”等关键词,可以找到大量由从业者分享的实践心得和代码示例。
- 在线课程:吴恩达的《机器学习》课程、李宏毅的《机器学习》课程中均有涉及集成学习的内容。
- 书籍:《机器学习实战:基于Scikit-Learn、Keras和TensorFlow》等书中对集成模型有详细介绍。
###
XGBoost作为机器学习工具箱中的一把利器,其价值已在工业界和学术界得到充分验证。学习它,不仅仅是掌握一个算法库,更是理解集成思想和模型优化实践的绝佳途径。学习之路始于足下,建议你立即按照上述路线图,从运行第一个“Hello World”般的XGBoost程序开始,逐步构建起自己的知识体系与实践能力。在人工智能基础软件开发的广阔天地里,精通XGBoost将为你增添一项极具竞争力的核心技能。
---
(注:本文内容整合了人工智能领域常见的学习路径与资源,旨在为初学者提供一个清晰的指引框架。具体学习时,请以官方文档和经典资料为准,并结合大量动手实践。)