人工智能的实施为何更难实现 聚焦基础软件开发的核心挑战
随着人工智能技术的蓬勃发展,其在各行各业的落地应用已成为不可逆转的趋势。许多企业和研究机构在实践中发现,将人工智能从概念转化为稳定、高效的实际应用,其难度远超预期,尤其是在基础软件开发层面。为何人工智能的实施如此艰难?其核心挑战深植于基础软件开发的复杂生态与独特需求之中。
技术栈的复杂性与快速演进构成了首要障碍。人工智能基础软件开发并非孤立存在,它依赖于庞大的技术生态系统,包括高性能计算框架(如TensorFlow、PyTorch)、数据处理工具、模型部署平台以及异构硬件(如GPU、TPU)的适配。这些组件迭代迅速,版本兼容性问题频发,开发团队必须持续跟进最新进展,同时确保现有系统的稳定性,这带来了巨大的维护成本和技能要求。
数据依赖性与质量瓶颈是另一重难关。人工智能模型的有效性高度依赖于大规模、高质量的数据。在基础软件开发中,数据往往存在稀疏、标注不一致、隐私安全受限等问题。构建可靠的数据流水线,实现数据清洗、增强和管理的自动化,需要跨领域的专业知识,且过程耗时费力,成为项目实施的关键瓶颈。
模型的可解释性与可复现性挑战突出。与传统软件不同,人工智能模型常被视为“黑箱”,其决策逻辑难以追溯。在基础软件开发中,这导致调试困难、错误排查成本高昂,并可能引发伦理与合规风险。确保模型在不同环境下的可复现性——即相同代码和数据产生一致结果——也因硬件差异、随机性等因素而难以实现,影响了系统的可靠部署。
算力资源的高需求与优化压力不容忽视。人工智能训练和推理过程通常需要巨大的计算资源,这对基础软件的架构设计提出了极致要求。开发人员需在模型精度、推理速度、能耗效率之间寻求平衡,并通过分布式计算、模型压缩等技术进行优化。这些优化往往需要深厚的算法功底和工程经验,门槛较高,且易受硬件限制影响。
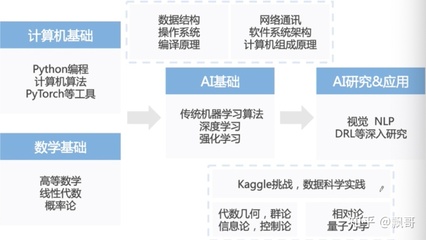
跨学科协作与人才短缺加剧了实施难度。人工智能基础软件开发融合了计算机科学、数学、领域知识(如医疗、金融)等多学科内容,要求团队具备复合型能力。当前,市场上既懂算法又擅工程的高端人才稀缺,加之跨部门沟通成本高昂,导致项目推进缓慢,甚至偏离实际需求。
人工智能的实施之所以更难实现,根源在于基础软件开发中技术生态的复杂性、数据质量的依赖性、模型透明度的缺失、算力资源的苛刻要求以及跨学科人才的匮乏。为突破这些瓶颈,行业需加强标准化建设(如统一接口与协议)、推动开源协作以降低开发成本、投资数据基础设施,并培养更多复合型技术人才。只有直面这些深层挑战,人工智能才能真正从实验室走向广阔的应用天地,释放其变革性潜能。
最新产品